以下文章来源于持续交付2.0 ,作者持续交付20
软件供应链安全,越来越受到关注。我们需要找到一种方式,来指导软件企业逐步改进。
本文来自 “小红花-技术管理探讨” 群组组织,那一科技公司贾枭的在线分享。
01
引言
现在与二十年前相比,软件进入市场的速度越来越快了,无论是 To C 消费领域的软件,还是 To B 企业应用的软件。而安全性现在仍旧会被绝大多数团队放在较低的关注度。
越来越多软件安全事件的发生,让整个行业对软件供应链安全越来越关注了。
随着系统变得越来越复杂,关键是要有检查和最佳实践来保证工件(Artifacts)的完整性,您所依赖的源代码就是您实际使用的代码。如果没有坚实的基础和系统发展规划,就很难集中精力对付下一次黑客攻击、破坏或妥协。
任何软件都可能给供应链带来漏洞。那么,如何评估你的软件供应链安全性呢?
02
SLSA 框架把握三大事项
Google 根据自身的软件工程经验,拟订了一个软件供应链安全框架,被称为「软件供应链的安全等级」,英文是 Security Levels of Software Artifacts,简称为 SLSA(发音:salsa)。
SLSA 是一个安全框架,
也是一个控制检查表,
用于防止篡改,提高完整性,
并保护项目、企业或企业中的软件包和基础设施。
供应链攻击是一种持续存在的威胁,它是利用软件的一个弱点来干扰软件的正常工作,甚至篡改系统数据。SLSA 框架建立了三个信任边界,鼓励采用正确的标准、认证和技术控制来强化系统,用于抵御这些威胁和风险。这意味着能够自动分析工件,保证源代码安全,防止构建和分发过程中可能发生的干扰,隔离任何隐藏的漏洞,并确定哪些系统组件可能受到影响。
SLSA 相当于把 Google 内部软件工程价值观以另外一种方式进行了国际化输出,主要是希望提高整个软件行业的工程管理水准。现在很多软件覆盖的面也越来越大了,软件出现一些问题以后,产生的代价也很大。
它就是一个检查清单,任何一个企业都可以拿着它一条一条的去比对。
它能给你一些可执行的一些操作的意见。
整个框架主要把握三大事项:
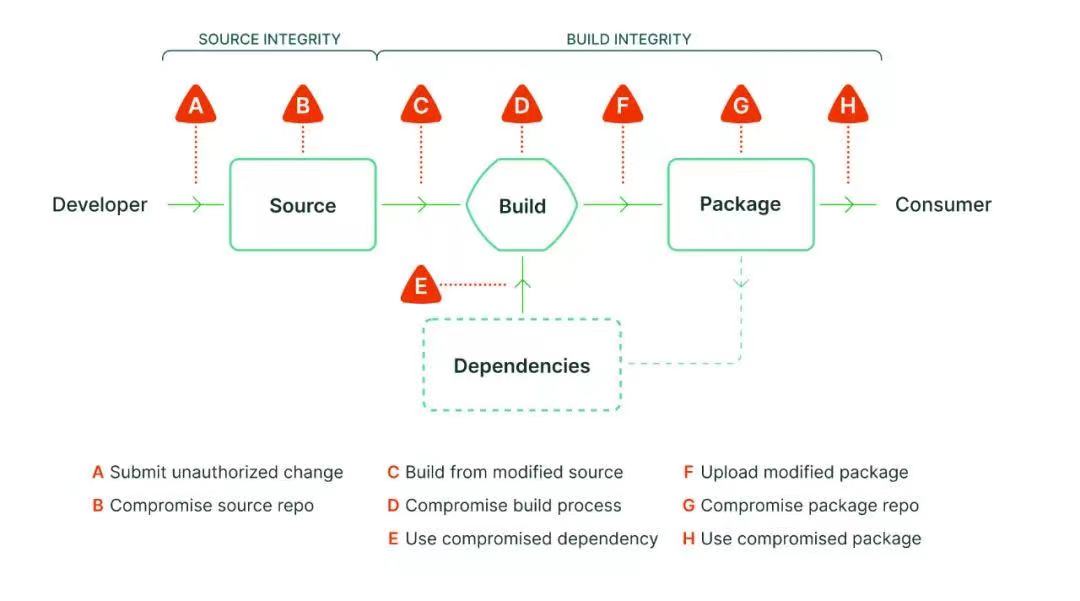
当提到安全时,第一个要思考的问题就是这个威胁可能来自于哪里?下图是 SLSA 提供给我们的一个框架:
03
七大常见风险点
上图中的左侧部分是关于源代码的质量安全。右侧部分是关于整个构建与分发过程的质量安全。图中下方,从 A 到 H 是所有可能出现的问题。
从最左侧做编码工作,然后提交改动到代码库里;然后代码库里面的内容再流动在整个 CI/CD(持续集成/持续部署) 的过程。
在软件构建环节中,你可能会用到一些来自第三方的依赖库,产生一个你自己的软件制品。然后放到你的制品仓库里被保存,最终流向消费者。
整个链路上有很多地方其实相当于上图中的每一个边或者一个这个框,每一处都可能出现一些风险。
第一个风险点 A:代码提交。开发者在提交代码时,有可能提交一些有风险的改动。这些有风险的改动有可能是故意的,也有可能是无意的。比如说,有一些是测试不完全的,有一些可能是应该做的检查和权限扫描,被绕过去了。同样,如果是一个人去攻击这个系统,就可以用类似的思路去攻击这些地方。
第二个风险点 B:代码仓库。比如,现在我们都用 Git。但 Git 本身也是可以覆盖历史版本的;或者一个人可以假冒另一个人的身份,在历史中插入一些你不想看到的提交(commit),这个过程就会产生很多潜在问题。
第三个风险点 C:检出源代码到构建机的过程。这个其实是我们比较容易忽略的地方。一般大家可能会着重说:“我要保护我的源代码和代码仓库。”但可能不太会关心整个 CI/CD 基础设施上的机器,包括它跟外部联网。
那么,怎么去保护呢?一个最简单的方式,比如在 CI 过程中,当从这个源代码仓库去读代码的时候,中间的网络如果没有经过加密连接,甚至有些人假设它是公司内网就足够安全的。这其实都是有潜在风险的。理论上,工程师可以在里面注入一些不干净的代码,最终让构建出来的东西成为不安全的制品结果。
第四个风险点 D :构建过程本身。如果构建系统中的机器本身被入侵了,或者你的整个构建过程不是标准化的(例如,很多企业在构建代码的时候是人工操作来执行的,或者最终发布之前是人工来进行发布的,那这个人的很多行为操作是不可控的),这就会产生很多风险。
第五个风险点 E:依赖包管理。这在最近一两年成了大家比较熟悉的风险点,特别是 nodeJS 生态里(或者一些别的生态里面),可能会有第三方依赖被污染的情况。
被污染后,有可能打了一些你不想看到的反动词句,或者用了一段时间后,第三方库无缘故地突然就消失了,或者故意引入一些死循环。这些问题会有很多,有的是出于政治或者一些个人喜好的问题,而还有一些可能是无意的。
再比如说,整个 NPM 生态里有一个很大的问题:如果你是某个 NPM 包的作者,你有权修改这个包;如果你用一个你自己控制的域名,并注册了邮箱,在 GitHub 上使用,当这个域名如果过期后,很可能被别人再次注册,那别人其实就可以伪造你的身份,上传一个有问题的包。这种攻击其实代价很低,只要去扫 NPM 所有作者的 Email 地址,看哪一个域名过期了就把它注册下来,剩下的事情就很简单了。所以这个风险点被攻击的可能是比较大的。
第六个风险点 F:从构建到上传到包管理的过程。这个过程其实大家都很熟悉。比如,有一些移动应用商店,当某个应用程序开发完以后,开发人员很可能在本地构建出一个包(或者有一个专门的发布工程师负责构建),手动上传到某个应用商店审核。上传过程是否会被影响,很难确保的。另外,上传包也需要身份认证。但是,如果密钥被泄露了,或者是有一些别的方式去直接修改这个包或仓库中的内容,那就会有很多风险。
第七个风险点 G:从包管理系统到客户手中的过程。这在很多年前比较常见的,比如说有一些软件下载站,会在原始的软件包里面放一些其他东西,比如广告、木马程序等。其实,现在对程序进行签名还不是一个特别普遍被重视的事情。
下面举个关于代码提交引入风险的例子。
04
举例:代码提交引入风险
2021 年有个新闻,某大学研究人员为了测试一下某开源项目的 Code Review 有多严格。于是,他主动去修复一个 issue,但同时也偷偷引入一个潜在的安全问题。
他想通过这种方式去看能否被人发现,当然他只是把它当作一种研究方式。但被发现后,他也被批评得很惨。
从防御的角度看,人工 Code Review 仍旧会有风险漏出的情况。但是,从另一个角度看,如果没有 Code Review,是不是风险会更大?
所以,在第一个风险点 A,我们的确需要引入 Code Review 机制,虽然不能完全避免风险,当然前提是「认真做」。
有些公司虽然有 Code Review 流程,但并不是强制的。代码可以不经过 CR,直接提交。这其实就相当于没有 CR 机制。
另外,在某些公司中,一个工程师可以用一个账号提交代码。他还可以用另外一个管理员帐号(他本人是管理员)审批这个代码提交。这在系统中看上去两个人,但事实上是一个人。
这在开源的场景可能性更高。因为,参与开源项目的可能来自天南地北的开发者,真实身份很难确定,大多只是一个 Email 地址。如果你有两个不同的 Email 地址,其实就有可能做很多奇怪的事情。
机器人帐号风险
很多公司或一些开源项目的系统中有一些「机器 人」,用于执行一些自动化任务。而通常,这个「机器人」有很大的权限。比如,持续集成系统其实就是个「机器人」,权限很大,可以下载你的所有代码,在谷歌,甚至还能提交很多自动化的改动。如果被人冒用了它的身份,可能会做很多事。
人类不易检视的内容
还有一类是很比较常见的,就是提交一些没有办法让人去审阅的修改。
比如,你有一个文本文件,里面存的了一长串的 Hash 码。这个 Hash 码指向某个第三方软件包,是那个软件包的 MD5。那么,你要更新到一个新版本,也找到了新的 MD5 码。你会更新这个文本文件中的 MD5 码,但作为审阅人,他有时可能并不能立刻明白。如果你要故意引入,或者是你取的软件包的连接没有被加密,你可能获得一个错误的 Hash 值。这对系统的影响是比较大的,因为下游所有系统都会信任这个 Hash。
对于上面这几关问题,SLSA 标准中也都要求你去解决。也就是说,你如果引入 Code Review 机制,那你就不能把它变成一个可选的,必须是一个强制环节。
05
SLSA 也有无能为力的时候
是否完全执行了 SLSA,就保障你完全安全了呢?绝对不是。
它允许一个代码在被 CR 以后,再被修改。这是 Google 的做法,主要是为了效率考虑。因为很多时候,可能只是有一个字写错了,一个单词拼写错了,而其它的的代码都是对的,或者,你只是修改了提交说明信息( commit message ),但是并没有修改代码本身。在 Google 内部,这种情况下,确实是允许直接提交,不再 Review。Google 的理由是,在后续很多环节去保证质量。
但这种做法,可能对其它公司是有非常有风险的。SLSA 之所以允许这么做,是因为 SLSA 是谷歌根据它自己真实软件工程实践总结出来的。但世界上只有很少的公司可以做到 Google 软件工程管理水平。
当然,公司内部人员有组织的故意搞事情,SLSA 也无能为力。这不在 SLSA 的考虑之内。
这根本不是技术问题。现在,很多网络安全事件并不是因为技术多牛,而是利用了社会工程学技巧。
所以,直接不看就通过的情况,不在 SLSA 框架之内考虑。
无论如何,将可以自动化的部分全部自动化是最好的。因为工具对某个问题,一般都会有一个统一且唯一的答案。比如说,「编码风格格式」这件事情,没有对错,工具直接格式化一下就好;行缩进到底是 2 个空格,还是 4 个空格,到底缩进到哪里等,没有那么重要。这种事情不应该成为 CR 中争论的问题,而应该是去看必须由人评判的事情。还有,能用静态分析工具找出来的安全问题,就先用工具找,只要工具说代码不行,那一定要修复。
能自动化就尽量多的使用自动化,使用自动化的人数越多,收益就越大。