近日,范特科技首席科学家汝骏仁博士以《开源AI大模型》为主题进行了线上分享,从开源模型、闭源模型、大模型发展历程、类ChatGPT及GPT4模型等方面全面介绍了大模型,以及大模型对当下人工智能发展的关键作用。小编基于汝骏仁博士的演讲,以第一人称呈现演讲内容,特整理成文字稿,供大家学习参考。
像OpenAI的ChatGPT/GPT4,谷歌的PaLM,还有现在大火的图像生成软件Midjourney,国内的文心一言、通义千问这些大模型产品都是闭源的,论文上怎么写都行,但作为算法人员就很难去复现。
所以,今天我讲的侧重点是开源大模型,那些我们可以获取模型权重本地部署,甚至根据场景数据进行微调,赋能到我们自己产品中,相对自主可控的大模型。毕竟谷歌也说了,在开源狂潮下,谷歌和OpenAI都没有护城河。
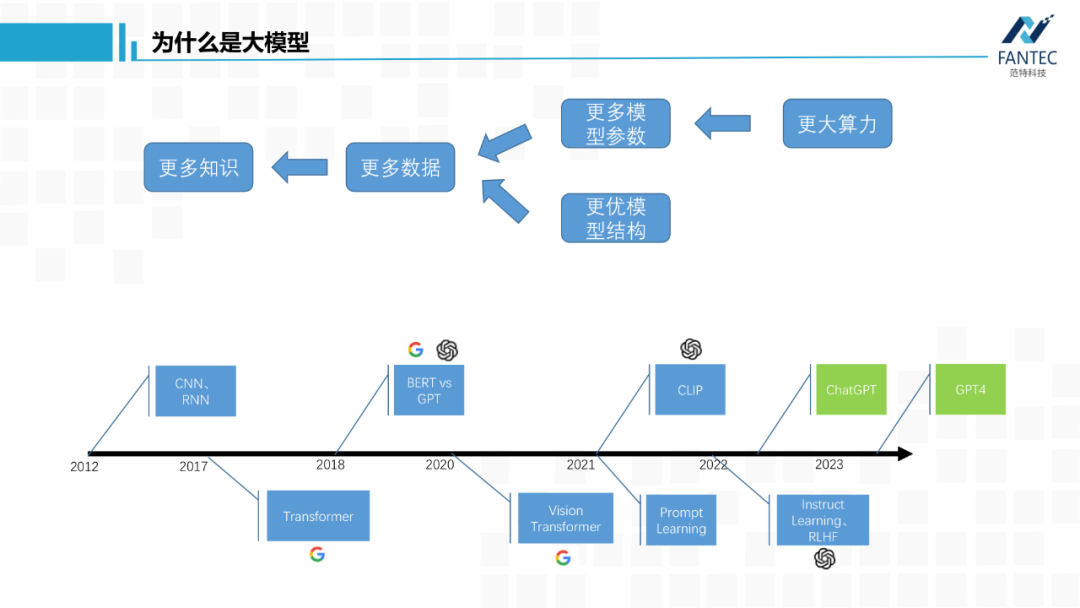
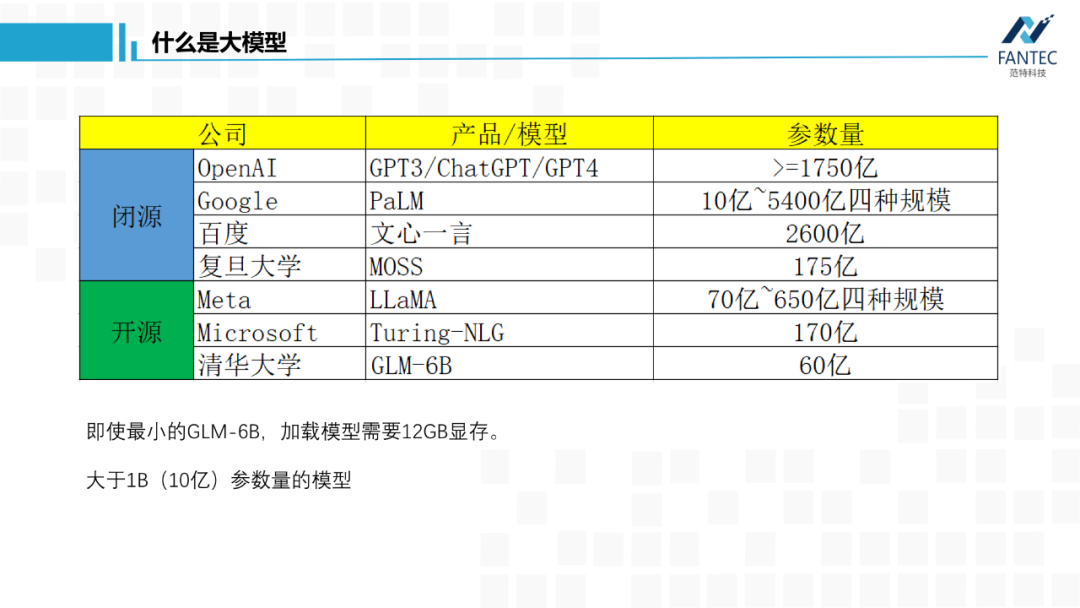
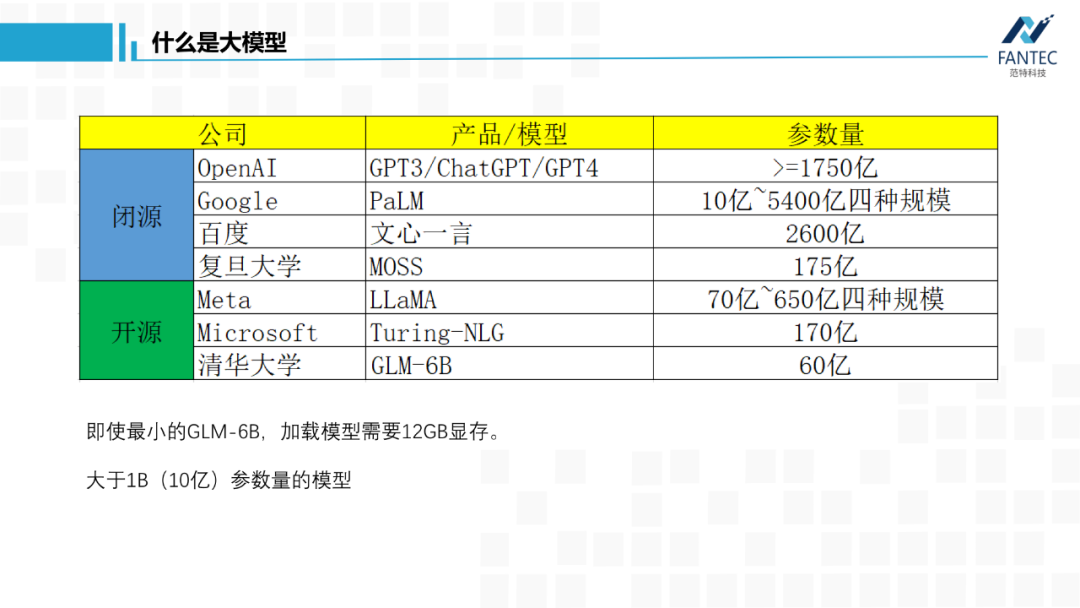 首先是OpenAI没有open的GPT3,官方称有1750亿参数。ChatGPT以它为底座进行指令微调和RLHF,理论上参数量没啥变化。GPT4加入了视觉模态,总参数量肯定会变大,但是量级肯定还是千亿。 然后是谷歌,几个月前的发布会上,支持BARD底层的PaLM-v1当场翻车,导致其股价大跌。这周谷歌带着PaLM-v2再战GPT,宣传模型参数量从10亿~5400亿分四个规模。然后是ChatGPT出来后,国内最早发声的复旦大学邱锡鹏老师团队的MOSS,官方称有175亿参数。 以上都是几个闭源的,参数量不一定真实,但量级应该大差不差。 Meta/Facebook泄露的LLaMA模型,从70亿到650亿参数量不等,是目前开源的语言底座大模型中最优秀的,应该没有之一。 微软的Turing-NLG有170亿参数,和上面的偏重于自然语言生成模型不同,它更擅长语言理解。 清华大学的GLM,它比ChatGPT早了一两个月出来,目前开源的只有60亿参数模型。可以看到,即使最小的GLM-6B,按半精度FP16保存,我们加载模型都会需要12G显存,像1080/2080这类消费级显卡就不行了。简单起见,今天提到的大模型,参数量都是在10亿以上,直观地看,本地权重文件至少2GB。再简单说下,为什么通用人工智能的路上,非大模型不可。 为了让模型学习到更多知识,就需要给它更多高质量数据,自然就导致训练数据分布变复杂,继而需增加模型中可学习的参数来更好地拟合分布,所以模型就变大了。 我感觉只要深度学习底层的万能近似定理和梯度下降找局部最优解这两个数学理论,没有被突破或替换,那依靠大模型才能消化大数据这个结论基本不会改变(这里的“消化”,指的是在训练集上的loss值,可以降得足够低,如果训练集都做不到,那更别提泛化能力了)。 当然通过设计更优模型结构和更优损失函数来提高模型的学习效率,也是必要的,但没有扩大参数量那么本质。综上所述,AGI必须大模型。 提到了模型结构,顺便看下它的进化史,你会发现ChatGPT对于谷歌,不单单是搜索引擎这样的产品之争,也是流派或者信仰之争。 Transformer出来前,CNN在玩它的图像,RNN玩它的文本、语音这类时间序列。而谷歌提出Transformer的初衷,是为了解决RNN无法并行计算和长时间记忆不强的问题,而自注意力机制恰好可以缓解这两个痛点。谷歌和OpenAI都对Transformer做了改进,将NLP引入了预训练、自监督时代。其中,谷歌的BERT只保留了encoder层,OpenAI的GPT只保留了decoder层,当时来看两者各有优势,BERT更擅长自然语言理解(比如文本分类),GPT更擅长自然语言生成(比如翻译和对话)。从此BERT派和GPT派遵从各自的信仰成长,期间谷歌也提出过像T5这样的encoder-decoder兼顾的模型。至此,RNN时代基本结束,文本、语音任务被Transformer统治。 谷歌提出了视觉Transformer,将图像Patch化构建token送入Transformer层,CNN被拉下神坛,图像/文本/语音跨模态融合成为可能。 OpenAI开源CLIP,实现图像和文本的特征对齐,学术界开始各种基于CLIP的二次创作。同一年,Prompt learning(提示学习)诞生,通过大模型预训练+下游任务做prompt,将所有NLP任务转化为了生成式任务。也就从那时起,谷歌的BERT系列开始落后于OpenAI的GPT系列,因为刚才提到过,GPT更适合文本生成。 Instruct Learning(指示学习)指令微调被提出,OpenAI再结合擅长的强化学习RLHF,调教出了ChatGPT。早在2017-2018年,OpenAI的强化学习模型就打败了DOTA2的冠军队伍,所以强化学习本就是他们的强项。有CLIP这样的多模态技术积累,OpenAI又发布了GPT4,可以进行跨模态的多轮聊天。
首先是OpenAI没有open的GPT3,官方称有1750亿参数。ChatGPT以它为底座进行指令微调和RLHF,理论上参数量没啥变化。GPT4加入了视觉模态,总参数量肯定会变大,但是量级肯定还是千亿。 然后是谷歌,几个月前的发布会上,支持BARD底层的PaLM-v1当场翻车,导致其股价大跌。这周谷歌带着PaLM-v2再战GPT,宣传模型参数量从10亿~5400亿分四个规模。然后是ChatGPT出来后,国内最早发声的复旦大学邱锡鹏老师团队的MOSS,官方称有175亿参数。 以上都是几个闭源的,参数量不一定真实,但量级应该大差不差。 Meta/Facebook泄露的LLaMA模型,从70亿到650亿参数量不等,是目前开源的语言底座大模型中最优秀的,应该没有之一。 微软的Turing-NLG有170亿参数,和上面的偏重于自然语言生成模型不同,它更擅长语言理解。 清华大学的GLM,它比ChatGPT早了一两个月出来,目前开源的只有60亿参数模型。可以看到,即使最小的GLM-6B,按半精度FP16保存,我们加载模型都会需要12G显存,像1080/2080这类消费级显卡就不行了。简单起见,今天提到的大模型,参数量都是在10亿以上,直观地看,本地权重文件至少2GB。再简单说下,为什么通用人工智能的路上,非大模型不可。 为了让模型学习到更多知识,就需要给它更多高质量数据,自然就导致训练数据分布变复杂,继而需增加模型中可学习的参数来更好地拟合分布,所以模型就变大了。 我感觉只要深度学习底层的万能近似定理和梯度下降找局部最优解这两个数学理论,没有被突破或替换,那依靠大模型才能消化大数据这个结论基本不会改变(这里的“消化”,指的是在训练集上的loss值,可以降得足够低,如果训练集都做不到,那更别提泛化能力了)。 当然通过设计更优模型结构和更优损失函数来提高模型的学习效率,也是必要的,但没有扩大参数量那么本质。综上所述,AGI必须大模型。 提到了模型结构,顺便看下它的进化史,你会发现ChatGPT对于谷歌,不单单是搜索引擎这样的产品之争,也是流派或者信仰之争。 Transformer出来前,CNN在玩它的图像,RNN玩它的文本、语音这类时间序列。而谷歌提出Transformer的初衷,是为了解决RNN无法并行计算和长时间记忆不强的问题,而自注意力机制恰好可以缓解这两个痛点。谷歌和OpenAI都对Transformer做了改进,将NLP引入了预训练、自监督时代。其中,谷歌的BERT只保留了encoder层,OpenAI的GPT只保留了decoder层,当时来看两者各有优势,BERT更擅长自然语言理解(比如文本分类),GPT更擅长自然语言生成(比如翻译和对话)。从此BERT派和GPT派遵从各自的信仰成长,期间谷歌也提出过像T5这样的encoder-decoder兼顾的模型。至此,RNN时代基本结束,文本、语音任务被Transformer统治。 谷歌提出了视觉Transformer,将图像Patch化构建token送入Transformer层,CNN被拉下神坛,图像/文本/语音跨模态融合成为可能。 OpenAI开源CLIP,实现图像和文本的特征对齐,学术界开始各种基于CLIP的二次创作。同一年,Prompt learning(提示学习)诞生,通过大模型预训练+下游任务做prompt,将所有NLP任务转化为了生成式任务。也就从那时起,谷歌的BERT系列开始落后于OpenAI的GPT系列,因为刚才提到过,GPT更适合文本生成。 Instruct Learning(指示学习)指令微调被提出,OpenAI再结合擅长的强化学习RLHF,调教出了ChatGPT。早在2017-2018年,OpenAI的强化学习模型就打败了DOTA2的冠军队伍,所以强化学习本就是他们的强项。有CLIP这样的多模态技术积累,OpenAI又发布了GPT4,可以进行跨模态的多轮聊天。 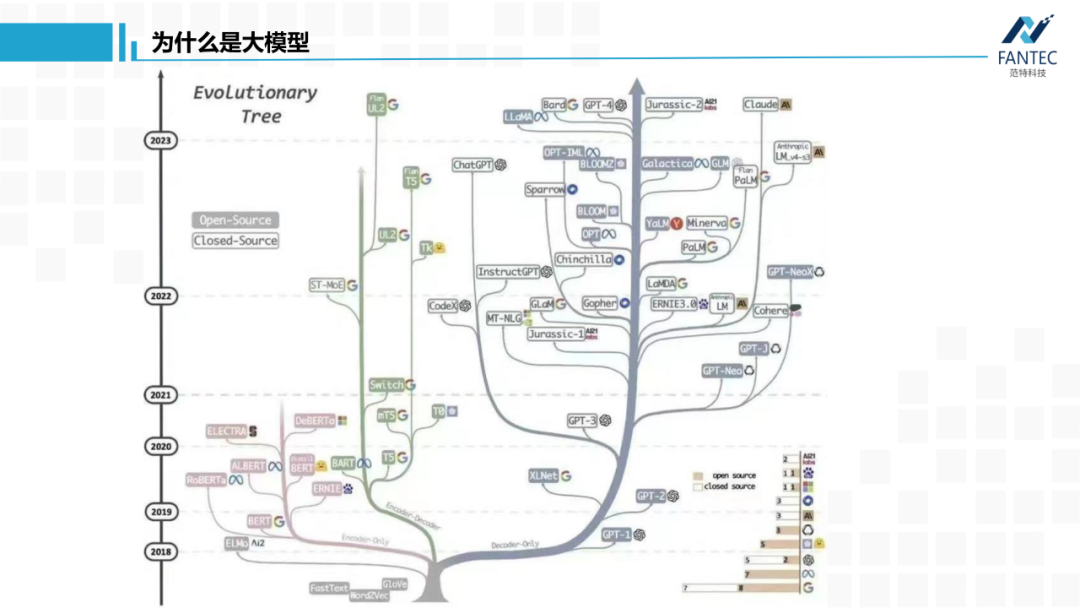
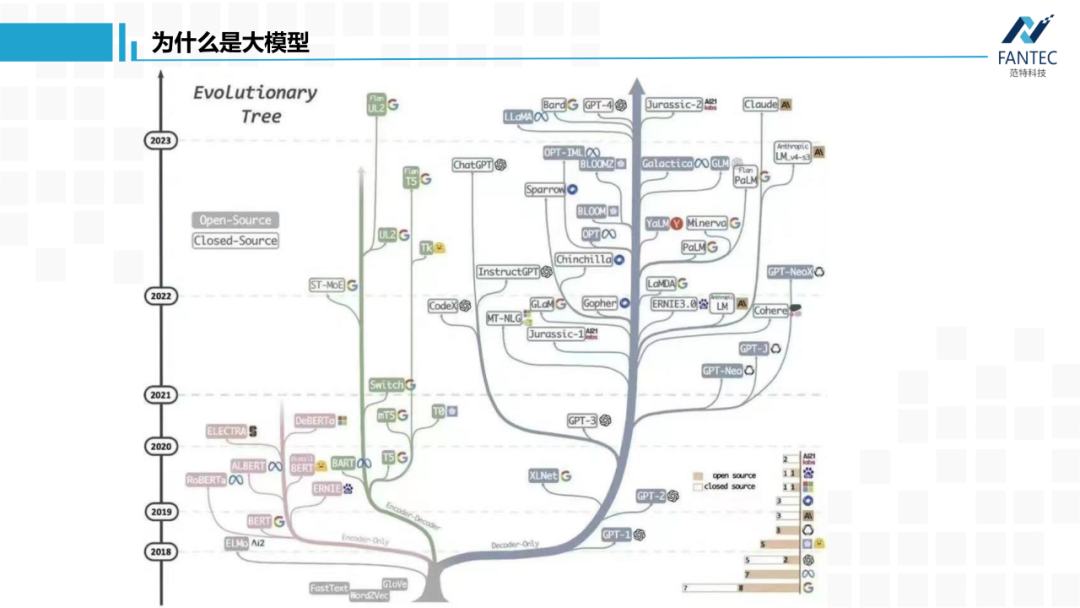
上面这张图展示了谷歌的BERT派和OpenAI的GPT派的发展历程,可以看到,BERT在2021年Prompt learning(提示学习)出现后,就没有更多进展了,反观GPT派很繁茂。更讽刺的是,谷歌现在用的PaLM系列,走的也是decoder-only这条路。
 说完OpenAI,为了方便后面讲各种模态的开源大模型,我想先让大家对ChatGPT和GPT4有个新的认识,其实它们并不复杂。 首先是ChatGPT,它本质上就是文本生成器,text to text。 比如当我问它“who are you?”后,他会把“who are you?”送入模型,模型预测出下一个出现概率最高的词是“I”,紧接着又把 “who are you?I”送入模型,模型预测出下一个出现概率最高的词是“am”。以此类推,直到预测出概率最高的词是一个结束符号。结束符号是什么,这跟你训练时用的词典有关,一般是一个自定义的特殊符号,这就完成了一轮对答。那当我问他第二个问题时,为何ChatGPT会有第一个问答的记忆呢?因为ChatGPT把第一次对话时的问题,第一次对话时的回复,以及第二次对话时的问题,三者串在一起送入模型,再模仿刚才一个字一个字地把第二次对话的答案反馈给我们。所以大家在使用ChatGPT时,它的答案不是瞬间全部返回,而是逐个单词地返回,并不是因为网速慢,而是模型就是这么推理的。所以,这就是一个概率游戏。 再看GPT4,它也是一个文本生成器,只是它每一次送进模型的内容有两个,一个是上一步为止的整个句子,另一个是对齐后的图像特征,输出依然是模型预测出的下一个出现概率最高的词。从模态上看,GPT4是将图像和文本输入模型,然后生成文本。至此,我们讲的大模型都是10亿以上的参数量,而且,通用人工智能必须要用大模型,以及ChatGPT只是一个“text to text”的文本生成器,GPT4是一个“text+image to text”的文本生成器。下面进入今天主题,开源大模型。
说完OpenAI,为了方便后面讲各种模态的开源大模型,我想先让大家对ChatGPT和GPT4有个新的认识,其实它们并不复杂。 首先是ChatGPT,它本质上就是文本生成器,text to text。 比如当我问它“who are you?”后,他会把“who are you?”送入模型,模型预测出下一个出现概率最高的词是“I”,紧接着又把 “who are you?I”送入模型,模型预测出下一个出现概率最高的词是“am”。以此类推,直到预测出概率最高的词是一个结束符号。结束符号是什么,这跟你训练时用的词典有关,一般是一个自定义的特殊符号,这就完成了一轮对答。那当我问他第二个问题时,为何ChatGPT会有第一个问答的记忆呢?因为ChatGPT把第一次对话时的问题,第一次对话时的回复,以及第二次对话时的问题,三者串在一起送入模型,再模仿刚才一个字一个字地把第二次对话的答案反馈给我们。所以大家在使用ChatGPT时,它的答案不是瞬间全部返回,而是逐个单词地返回,并不是因为网速慢,而是模型就是这么推理的。所以,这就是一个概率游戏。 再看GPT4,它也是一个文本生成器,只是它每一次送进模型的内容有两个,一个是上一步为止的整个句子,另一个是对齐后的图像特征,输出依然是模型预测出的下一个出现概率最高的词。从模态上看,GPT4是将图像和文本输入模型,然后生成文本。至此,我们讲的大模型都是10亿以上的参数量,而且,通用人工智能必须要用大模型,以及ChatGPT只是一个“text to text”的文本生成器,GPT4是一个“text+image to text”的文本生成器。下面进入今天主题,开源大模型。 上个月,陆奇以《我的大模型世界观》为主题进行了演讲,他提到“论文和代码都实在是跟不上”,让同事整理“大模型日报”。确实近几个月大模型的发展太快了,别说论文了,我感觉公众号上推送的新模型内容都来不及消化。接下来讲到的大模型,基本都是范特科技团队试过,感觉不错的。主要分为两大类,第一类是类ChatGPT和GPT4模型,如果想要本地离线部署相似应用,或者在自己的场景数据集上微调出自己的个性化聊天机器人,它们是不错的选择;第二类是模态更加多样化的大模型,组合使用它们可以丰富自己的现有产品。 首先是类ChatGPT,刚才提到过,Meta开源的LLaMA大语言模型底座是目前最优秀的,所以很多开源项目都是基于LLaMA做指令微调。最早的是斯坦福的alpaca,中文名“羊驼”,不仅开源了微调方法,而且开源了如何借助ChatGPT生成训练数据的方法,之后各种以动物命名的微调模型基本都是基于它的二创。其中,最优秀的是这个Vicuna(小羊驼),在UC伯克利发布的开源大模型排行榜中占据第一位置,这个测试只是针对英文的。 之后,StabilityAI团队(也就是开源Stable Diffusion的团队)模仿OpenAI把RLHF融入了Vicuna,开源了StableVicuna,号称有ChatGPT 90%的能力。所以如果不想自己微调个性化模型,也不介意使用英文,直接本地部署StableVicuna是个不错的选择。 Colossal-AI是新加坡国立大学尤杨老师的创业公司开发的,该公司专注NLP多年,它不仅支持指令微调,还开源了大模型中做强化学习的代码。 LMFlow是香港科技大学研究团队开发的,它除了单模态的语言模型,还开源了微调多模态模型的方法,一会儿将提到。 以上都是英文的,主要原因是LLaMA的中文语料在训练集中占比不到1%,虽然它有了强大的知识储备,但是沟通方式只对英文比较友善。所以自然有人会对它做中文化改造。 比如Chinese-vicuna,用中文指令集进行指令微调。还有BELLE,针对LLaMA做了中文词表扩充和中文预训练。 最后是清华大学的ChatGLM,它基于自己的底座模型GLM进行指令微调,中英文效果都行,目前只开源了6B,它是这里唯一一个encoder-decoder架构的大模型。 再来看GPT4,图像+文本生成文本的替代方案。最早的是LLaVA,也是由港科大开源,语言底座延续了LLaMA,视觉底座用的CLIP的Vit分支,不仅开源微调方法,还开源数据生成方法。然后,又有人把它的底层做了升级以及再升级。其实,基于底座大模型做指令微调,成本也不大,范特科技也做了许多尝试。
上个月,陆奇以《我的大模型世界观》为主题进行了演讲,他提到“论文和代码都实在是跟不上”,让同事整理“大模型日报”。确实近几个月大模型的发展太快了,别说论文了,我感觉公众号上推送的新模型内容都来不及消化。接下来讲到的大模型,基本都是范特科技团队试过,感觉不错的。主要分为两大类,第一类是类ChatGPT和GPT4模型,如果想要本地离线部署相似应用,或者在自己的场景数据集上微调出自己的个性化聊天机器人,它们是不错的选择;第二类是模态更加多样化的大模型,组合使用它们可以丰富自己的现有产品。 首先是类ChatGPT,刚才提到过,Meta开源的LLaMA大语言模型底座是目前最优秀的,所以很多开源项目都是基于LLaMA做指令微调。最早的是斯坦福的alpaca,中文名“羊驼”,不仅开源了微调方法,而且开源了如何借助ChatGPT生成训练数据的方法,之后各种以动物命名的微调模型基本都是基于它的二创。其中,最优秀的是这个Vicuna(小羊驼),在UC伯克利发布的开源大模型排行榜中占据第一位置,这个测试只是针对英文的。 之后,StabilityAI团队(也就是开源Stable Diffusion的团队)模仿OpenAI把RLHF融入了Vicuna,开源了StableVicuna,号称有ChatGPT 90%的能力。所以如果不想自己微调个性化模型,也不介意使用英文,直接本地部署StableVicuna是个不错的选择。 Colossal-AI是新加坡国立大学尤杨老师的创业公司开发的,该公司专注NLP多年,它不仅支持指令微调,还开源了大模型中做强化学习的代码。 LMFlow是香港科技大学研究团队开发的,它除了单模态的语言模型,还开源了微调多模态模型的方法,一会儿将提到。 以上都是英文的,主要原因是LLaMA的中文语料在训练集中占比不到1%,虽然它有了强大的知识储备,但是沟通方式只对英文比较友善。所以自然有人会对它做中文化改造。 比如Chinese-vicuna,用中文指令集进行指令微调。还有BELLE,针对LLaMA做了中文词表扩充和中文预训练。 最后是清华大学的ChatGLM,它基于自己的底座模型GLM进行指令微调,中英文效果都行,目前只开源了6B,它是这里唯一一个encoder-decoder架构的大模型。 再来看GPT4,图像+文本生成文本的替代方案。最早的是LLaVA,也是由港科大开源,语言底座延续了LLaMA,视觉底座用的CLIP的Vit分支,不仅开源微调方法,还开源数据生成方法。然后,又有人把它的底层做了升级以及再升级。其实,基于底座大模型做指令微调,成本也不大,范特科技也做了许多尝试。
我们基于LLaMA-7B在200W中文指令数据集上进行了微调,得到了范特通用版。再在300多条基金QA数据上进行微调,得到范特金融版。可以发现,对于“主板市场”这个带歧义的名词,金融版会默认金融领域的相关概念。同时,在提出第二个问题时,由于第一个问题和答案也被一起送入了模型,所以它获取到了“主要玩家”针对的就是“主板市场”这一概念。
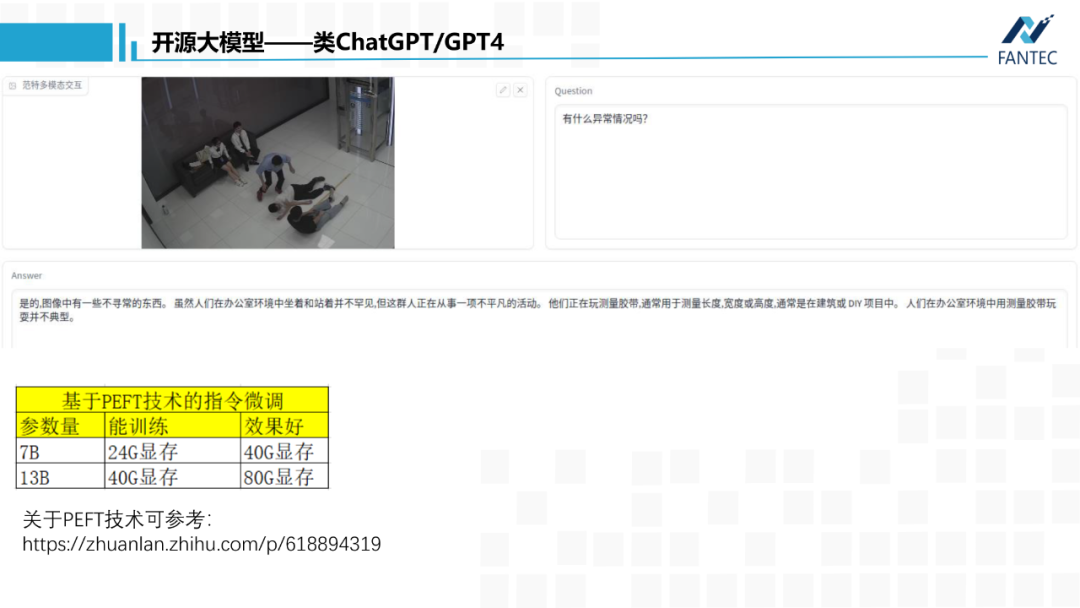
虽然刚才三个GPT4开源项目都是英文的,我们尝试将语言和视觉两个底座模型换成中文,并将项目中开源的指令集翻译成中文,模型微调之后,也能获得一个中文版的基于图像和文本的文本生成器。
当然,我们的模型跟ChatGPT和GPT4,在内容丰富性以及记忆长度上还有很大差距,一方面是数据原因,另一方面由于算力限制,我们在微调时必须采用像LoRA这类PEFT技术,参数的高效微调方法,它会冻结底座模型所有参数,只新增百兆大小的权重文件进行优化,虽然这种技术让中小企业具备了定制化大模型的能力,但效果上肯定不如参数全放开的微调方式。
这里我给出了基于PEFT技术微调模型的算力要求:微调7B大小的模型,至少要24G显存,比如RTX3090、A10,如果要较好的效果,建议40G显存,比如阉割版A100、RTX6000。而13B模型,分别要40G显存和80G显存,比如A100、H100、A800。
以上是开源的类ChatGPT和GPT4项目,下面我们来看其他各种模态变化的开源大模型。
在看这一部分时,各位可以着重关注每个模型输入输出模态上的变化,先不管原理。
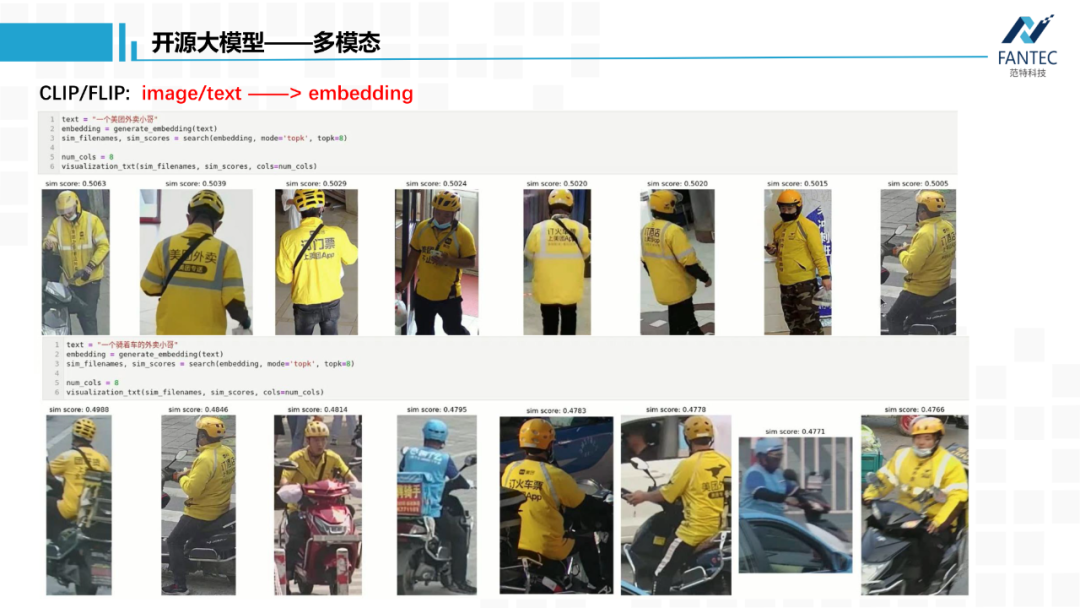
首先是多模态的开山之作CLIP,它将文本和图片转换为特征向量,并实现了特征对齐,这种特征对齐带来最直接的应用就是做检索,用文本检索图片库,用图片检索文本库。
下图是范特科技系统已经上线的功能,在某市公安局的实时人像抓拍库里,如果用“一个美团外卖小哥”作为文本query进行检索,系统会根据相似度大小从高到低输出这么一组检索结果。同理“一个骑车的外卖小哥”的输出结果。这种能力为客户提供了一种开集检索方式,而不是之前固定的物体类别、颜色等。
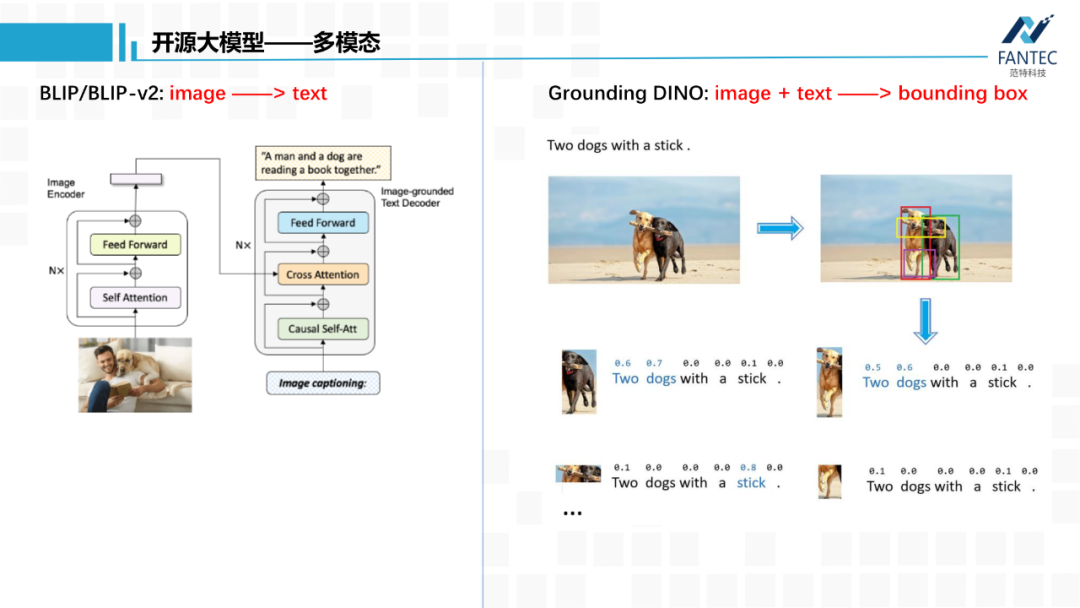
BLIP/BLIP-v2除了做图像和文本的特征对齐,还可以将图片转为文字,就是看图说话,这和Stable Diffusion恰好反过来。
Grounding DINO,输入一张图片和一段文本,模型会输出文本中语义相关的物体位置信息。这个对于做计算机视觉的人来说很友好,它避免了之前目标检测任务基于特定数据集特定类别的限制,比如COCO 80个类别,Object365 300多类别,开启了开集目标检测的大门。
Tag2Ttext,先从图片中提取名词tag,再根据名词tag的word embedding和图片embedding融合起来生成一段画面描述。和刚才的BLIP有些交集,但是它的中间环节tag往往更有用。
SAM,是今年META放的第一个大招,全称是Segment Anything,顾名思义,将画面中所有物体进行实例分割,并且开启了视觉prompt的大门。它可以接受点、框、涂鸦、文本四种类型的提示,输出对应目标的Mask。
举个例子,如果我们将下图画面中的五角星这个点坐标作为prompt,模型就会输出这辆车的Mask。这个功能可以和AR眼镜相结合,通过识别两眼关注点的坐标点作为Prompt,返回人眼目前聚焦物体的完整Mask。就SAM这个模型的应用展开讲,都可以单独讲好久,十分强大。

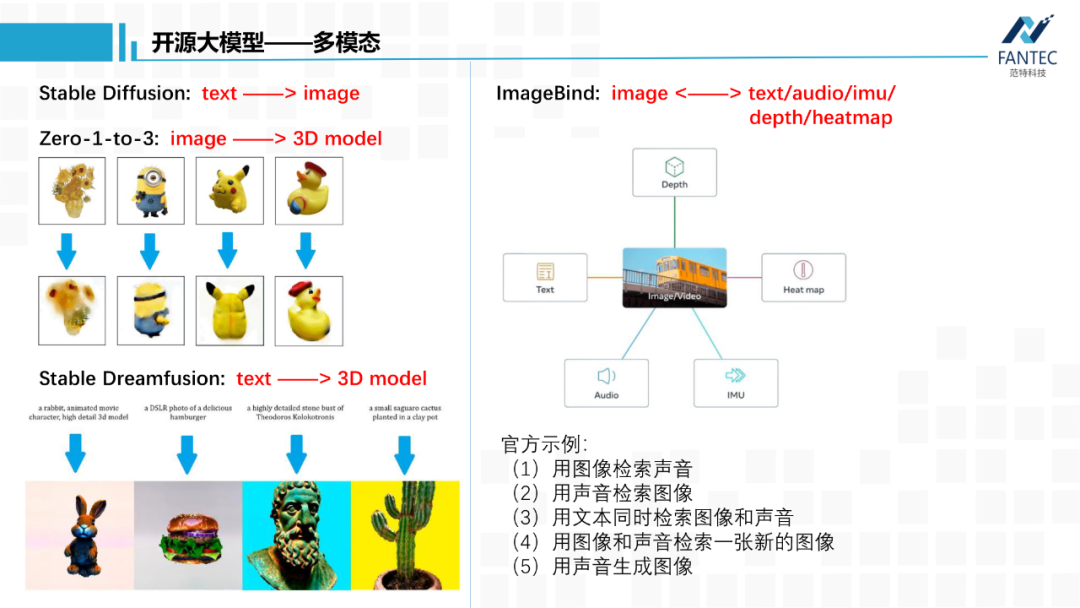
ImageBind,是META今年的第二个大招,5月上旬刚出来,通过视觉RGB模态为媒介,打通了文本、语音、深度图、热力图、惯导之间的模态联系。除了模型权重,官方给出了5个示例,前三个示例说明ImageBind已经对文本、图像和声音三种模态进行了特征对齐。
第四个示例什么意思呢?举个例子,输入一张苹果的图片和一段河水流淌的声音,模型会从图片库中检索出一张水龙头下洗苹果的图片。这个模型还支持深度图,IMU惯导这类移动端传感器数据,META依旧是在做它的METAVERSER。
最后我们看一下2D和3D的创作,这块可能是WEB3感兴趣的内容。
Stable Diffusion,实现了文字到图片,目前开源到了2.0版本。5月12日,它们的新产品可以根据图片文字生成视频,不过功能还需要付费。
Zero-1-to-3,可以实现单张背景干净的图片生成一个3D模型。
Stable dreamfusion,则可以根据一段文字描述来生成一个3D模型。
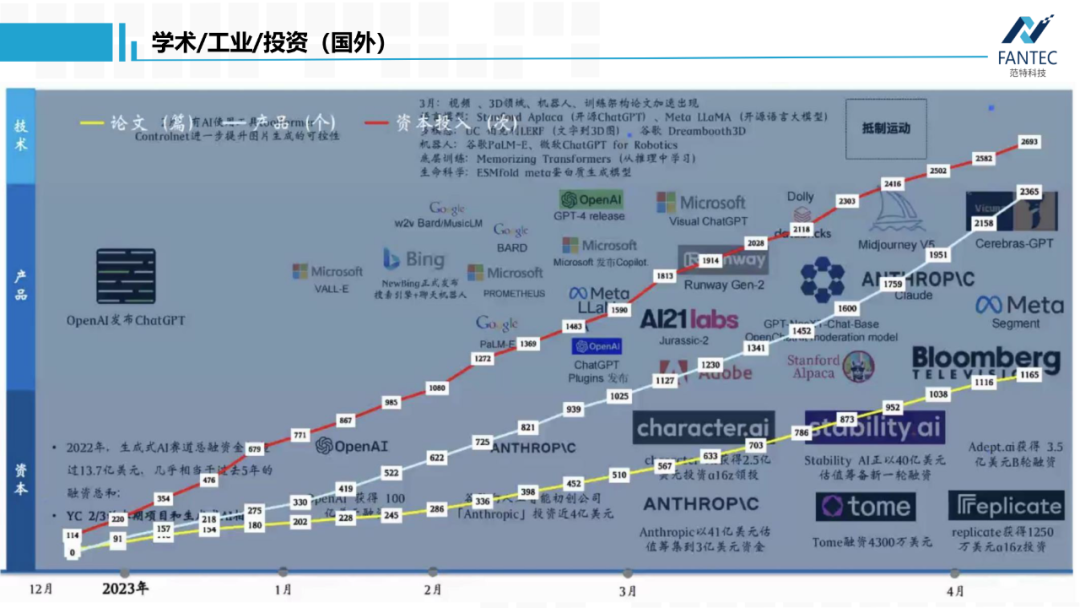
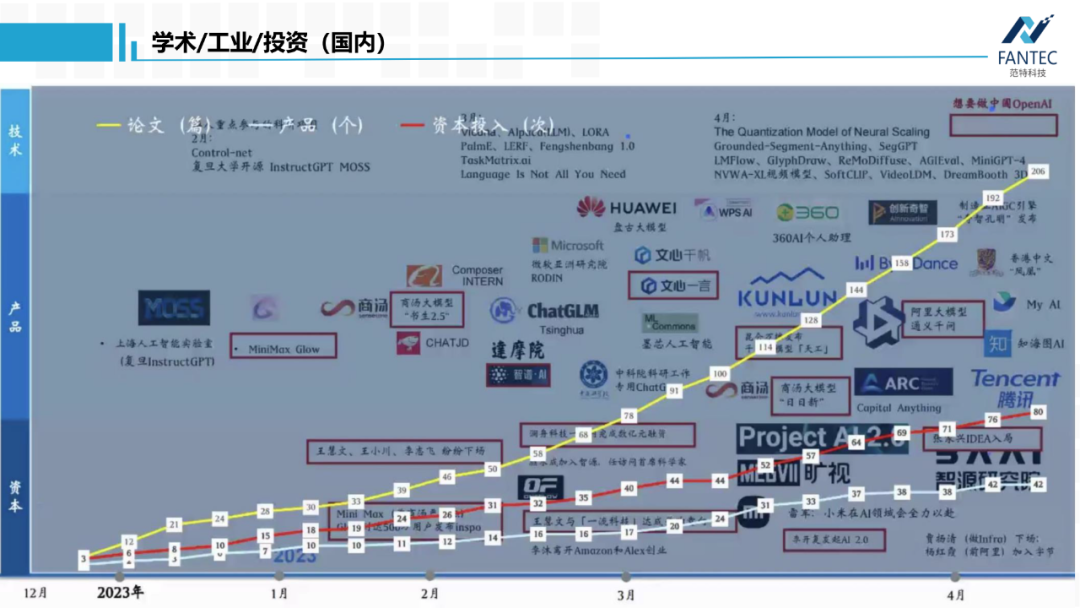
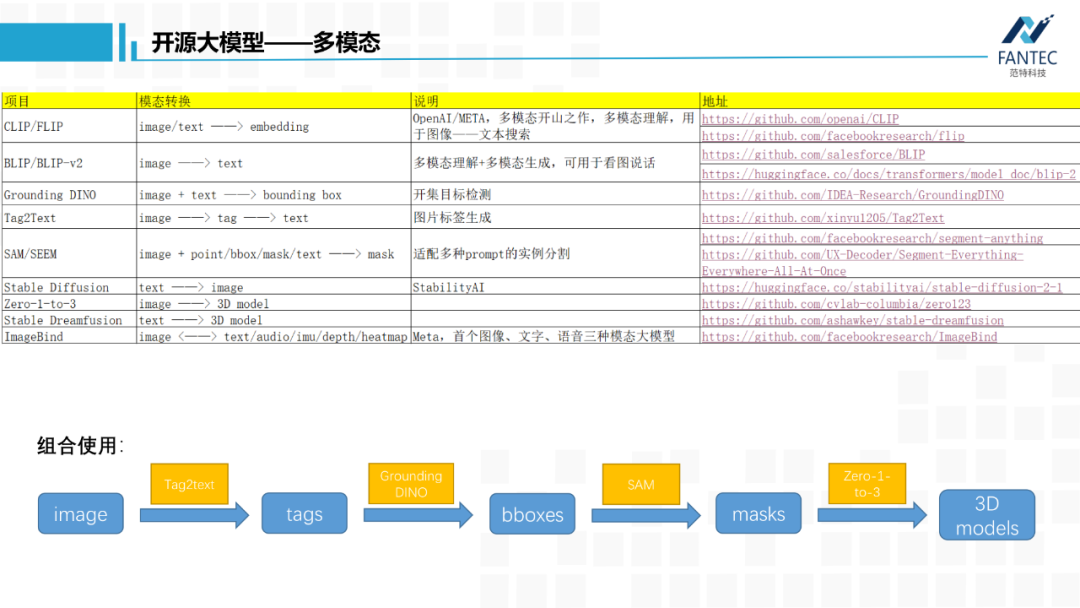 以上就是9个多模态转换的开源大模型,我们可以组合使用它们做些有趣的应用。比如:一张图片,先用tag2text生成tag,然后用Grounding DINO检测这些类别的bounding box,将bounding box作为prompt给到Sagment Anything,返回这些目标的背景干净的裁剪图,最后给到Zero1-to-3,理论上可以全自动地将图片中所有物体进行单独地三维重建。以上就是我想要分享的开源大模型,最后我们看一下,从2022年12月ChatGPT发布到现在,国内外在大模型领域,学术界论文数量、工业界产品数量、创投界投资数量的变化和趋势。首先是国外的,三者基本线性相关,都已达到四位数,而且是资本领衔,产品紧跟。
以上就是9个多模态转换的开源大模型,我们可以组合使用它们做些有趣的应用。比如:一张图片,先用tag2text生成tag,然后用Grounding DINO检测这些类别的bounding box,将bounding box作为prompt给到Sagment Anything,返回这些目标的背景干净的裁剪图,最后给到Zero1-to-3,理论上可以全自动地将图片中所有物体进行单独地三维重建。以上就是我想要分享的开源大模型,最后我们看一下,从2022年12月ChatGPT发布到现在,国内外在大模型领域,学术界论文数量、工业界产品数量、创投界投资数量的变化和趋势。首先是国外的,三者基本线性相关,都已达到四位数,而且是资本领衔,产品紧跟。再看国内,学术界的论文量是领先的,而且较产品和投资数量是指数级的增长趋势。所以,具有雄厚资金实力的国内科技企业应该抓紧时间了。